Method
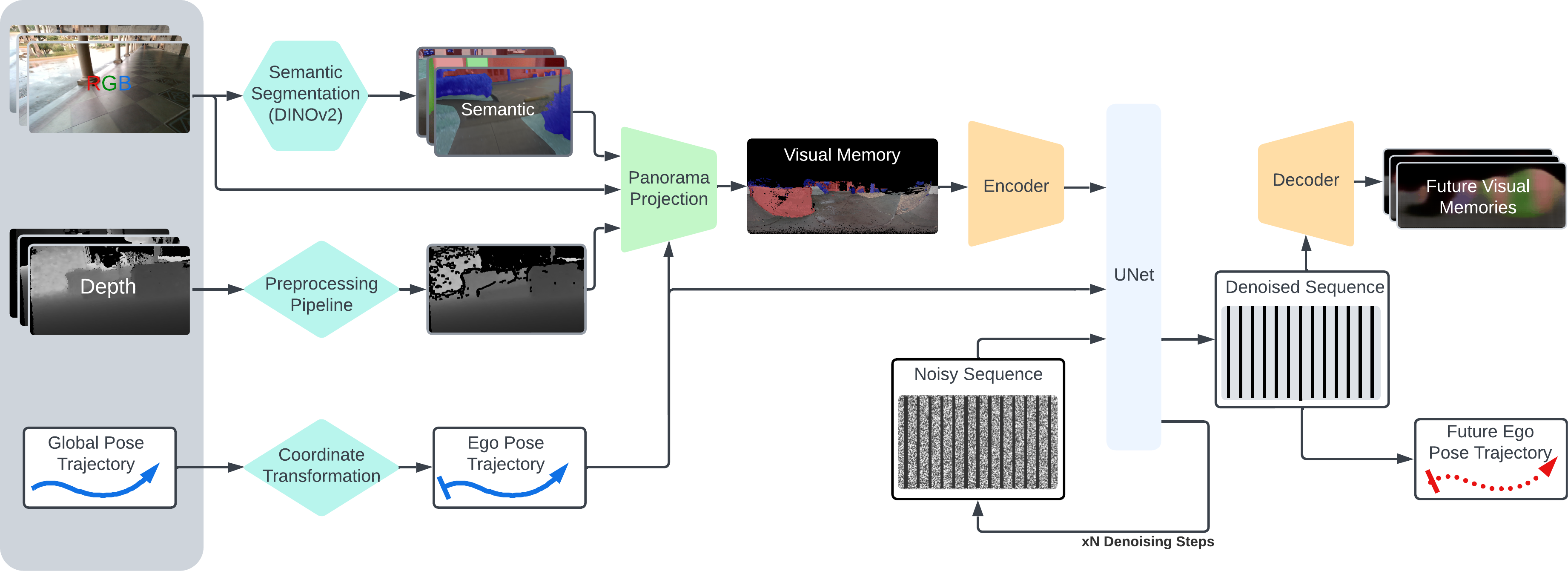
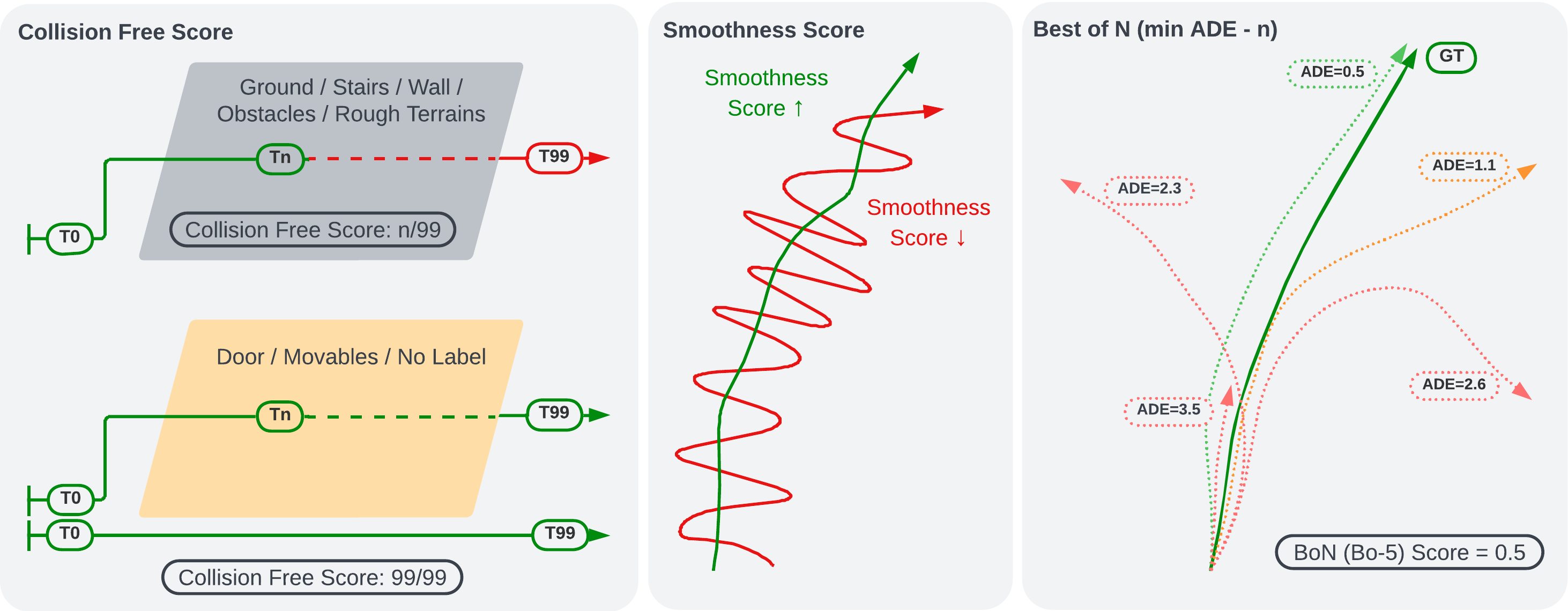
The goal of this work is to predict the possible paths of a person in a cluttered environment. A trajectory is defined as a sequence of 6D poses (translation and orientation) of a person navigating in the 3D world. At each time step t, our model uses the past trajectory to predict likely future trajectories. In addition, the prediction must be conditioned on the observation of surroundings. The visual observation S encodes the appearance, geometry, and semantics of the environment captured by wearable visual and depth sensors.
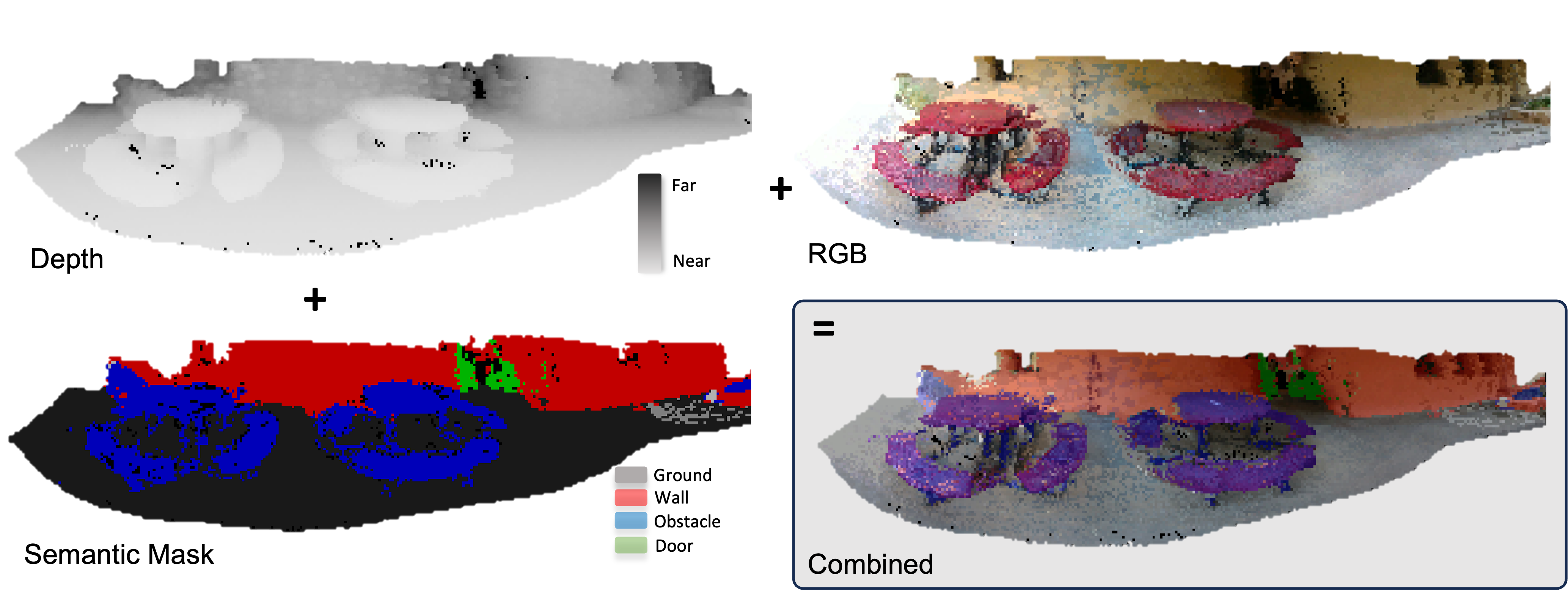
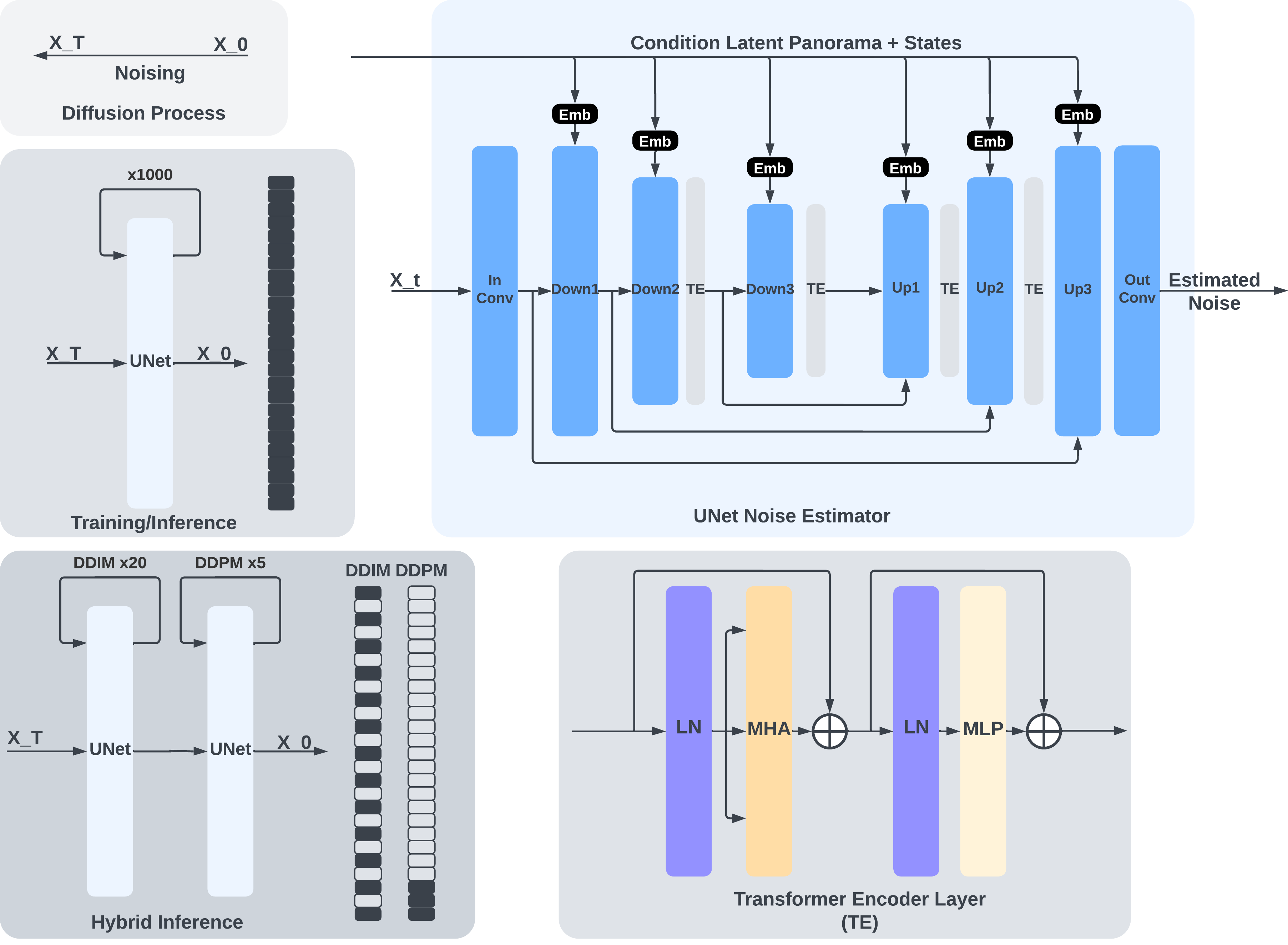
Therefore, our method takes in the past trajectory of the person and a short history of RGBD images. The color images are semantically labeled by DINOv2 into 8 semantic channels, while the depth images go through a preprocessing pipeline that filters out erroneously filled edges. We transform the past trajectory from a global coordinate frame to an egocentric frame defined by the gravity vector as -Z and forward-facing direction as +X. The collected images are them project and globally aligned to create a single panorama in the egocentric coordinate frame, referred to as "visual memory". Conditioning on the visual memory and the past ego trajectory, a diffusion model is trained to predict the future trajectory, along with encoded visual observations as auxiliary outputs. Finally, we use the VAE decoder to recover the expected future panorama. Combining with the hybrid generation method illustrated in the later section, we aim to provide a fast and effective method in predicting the distribution of the future states conditioning on the observed environment.